Multi-Document Abstractive Summarization
A multi-document abstractive summarization system built by combining hybrid embeddings and optimized transformer models to generate high-quality research summaries.
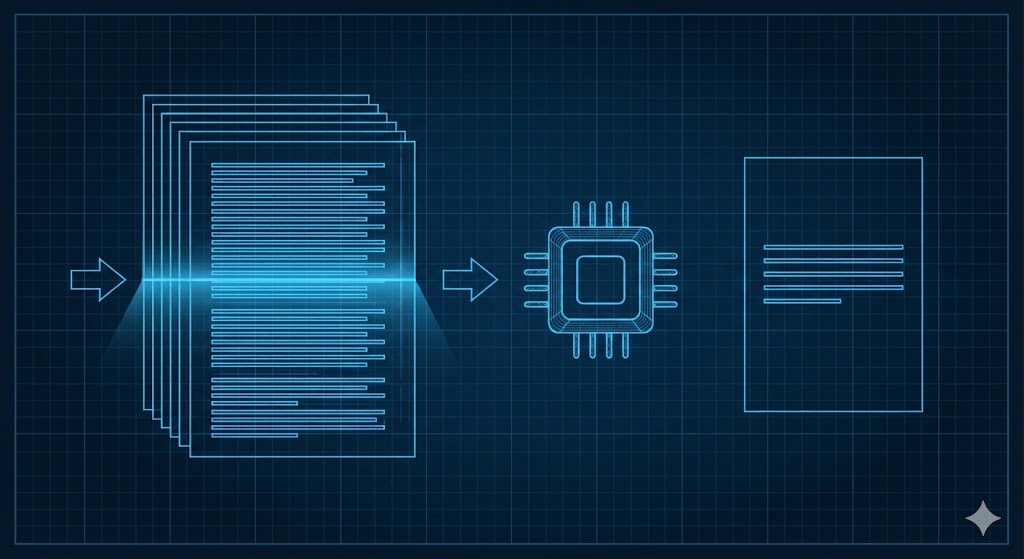
Multi-Document Abstractive Summarization System for Advanced Research
Challenge
Researchers today face an overwhelming volume of academic papers, reports, and documents. Manually reviewing and condensing large collections of text is slow, error-prone, and mentally taxing—especially for complex research topics. The PhD project required a multi-document abstractive summarization system capable of reading, understanding, and synthesizing information from many documents into a coherent, meaningful summary. The goal was to significantly reduce manual effort and deliver summaries that preserve context, novelty, and clarity.
Our Solution
We developed a powerful summarization pipeline that blended multiple embedding techniques with optimized transformer models. Instead of relying on a single method, we created hybrid text representations using Word2Vec, FastText, GloVe, and custom embeddings to capture deeper semantic meaning across documents.
On top of this, we integrated a set of refined generative models—similar to BART, Pegasus, and T5—enhanced through optimization techniques such as ACO, firefly algorithms, and lightweight reinforcement learning. The result was a system that could:
- Understand multiple long documents
- Extract core ideas, patterns, and connections
- Generate high-quality abstractive summaries
- Maintain consistency and reduce redundancy
- Adapt to different domains and writing styles
We also ensured the system remained modular, allowing the PhD researcher to experiment, tune, and extend components for academic evaluation.
Impact
The solution drastically improved the efficiency and quality of the summarization process. Instead of spending hours reading through multiple papers, researchers could obtain clean, structured summaries within minutes. The hybrid embedding approach helped retain subtle context and nuance, while the enhanced transformer models produced summaries closer to human-written quality.
Beyond easing workload, the system opened doors for applications in literature reviews, academic writing assistance, policy analysis, and large-scale document management.
Outcome
The project led to a robust, research-grade summarization framework that supported the PhD candidate’s thesis objectives. It demonstrated how advanced NLP techniques can meaningfully assist academic research and delivered outputs suitable for publication and scholarly evaluation. The final system stood as both a working prototype and a strong academic contribution.